データベースとは?エクセル利用者のための入門ガイド

こんにちは、3Min APIの開発をリードしているyeonghyeonです。
これまでの記事で、Chae-wonさんも私も「データベース」という言葉を何度も使ってきました。Webhookを説明するときも、JSONやスキーマを話すときも、AI時代のデータ準備について語るときも、欠かせない言葉でした。
ところが、「データベースとは何か」を正面から扱ったことは一度もありませんでした。今日はこの言葉をしっかり固めておきます。これから続くAPI、JSONシリーズの最初のピースです。
📚 非開発者のためのデータ基礎 3部作
- データベース —— データを入れる器(このページ)
- API —— 安全に出入りする窓口
- JSON —— やり取りするメッセージの形
この記事の目的は一つです。データベースという言葉の裏にある複雑な技術を勉強する前に、まず「自分のビジネスのデータを頭の中ではなく、表として整理する感覚」をつかむこと。この感覚さえ身につけば、残りは必要になったときに自然とついてきます。ですから前提知識はなくても大丈夫です。エクセルを「表形式でデータを整理するツール」程度に知っていればスムーズですし、それすらなくても本文で一緒に見ていきますので、気楽に読み進めてください。
データベースとは何か
辞書的な定義から始めます。ウィキペディアはデータベースを「体系的に整理されたデータの集合」と説明しています。技術用語では、これを保存・管理し検索できるようにするシステムをDBMS(DataBase Management System)と呼びますが、日常ではこの二つをまとめて「データベース(DB)」と呼びます。
一行で要約するとこうです。
データベース = データを構造化して保存し、素早く見つけ、多くの人が同時に使えるように作られたシステム。
この定義を無理に暗記する必要はありません。実は皆さんはすでに複数の「データベース」を毎日使っているからです。
日常の中のデータベース
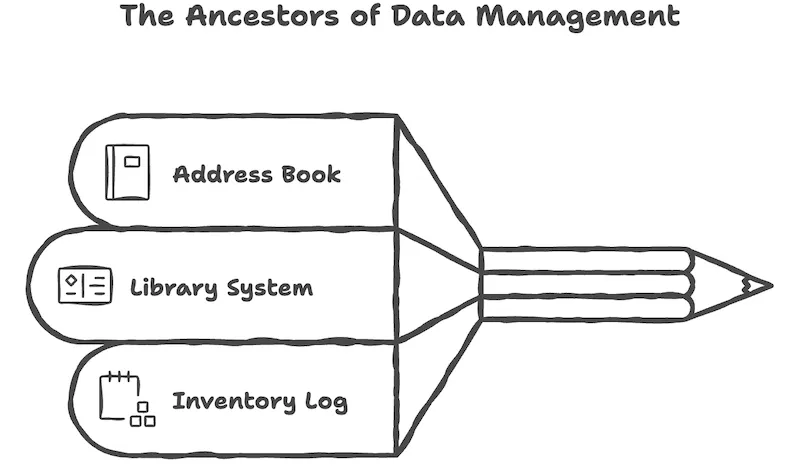
次の三つを思い浮かべてみてください。
- 住所録:名前、電話番号、住所が一行ずつ整理されています。特定の名前を探せばすぐに番号が出てきます。
- 図書館の貸出カード:本ごとにカードがあり、誰がいつ借りたかが記録されています。借りたら書き込み、返したら消します。
- コンビニの在庫台帳:商品名、数量、入荷日が書かれています。売れたら減らし、入荷したら増やします。
三つの共通点が見えますか? 決まった形式があり、同じ形のデータが繰り返し積み重なり、必要なときに素早く検索できるという点です。これがデータベースの本質です。紙であれ、エクセルであれ、専用サーバーであれ、道具が変わるだけで原理は同じです。
データベースの種類
現代のデータベースは用途によっていくつかの種類に分かれます。軽く見ておきましょう。
- 関係データベース(Relational、RDB):最も広く使われ、最も古い方式です。データをエクセルのように「表」で保存し、表同士を関係で結びます。MySQL、PostgreSQL、Oracleなどがここに属します。
- ドキュメントデータベース(Document):表ではなくJSONのような文書を丸ごと保存します。構造が頻繁に変わるデータに向いています。MongoDBが代表的です。
- グラフデータベース(Graph):人と人、物と物の「関係」自体を中心に置きます。ソーシャルネットワークや推薦エンジンに適しています。
- ベクトルデータベース(Vector):AI時代に登場した方式です。テキストや画像を数値の配列として保存し、「意味が近いもの」を素早く見つけます。
今日の記事はこの中で最も広く使われ、ビジネスの現場で基本となる関係データベースに集中します。
ワインショップ店主の話
理論だけではピンと来ません。実際の状況を追いかける方が早いです。
皆さんが小さなワインショップを開いた店主だと想像してみてください。最初は店舗一軒、お客さんも一日に数人だけです。ビジネスが育つにつれて、データを管理する方法も一緒に育っていきます。
ステージ1:手書きの台帳
オープン初期はノート一冊で十分です。日付、お客さんの名前、ワインの名前、金額。この四つをその日のうちに書き留めておきます。一日にお客さんが5人なら5行、10人なら10行です。
この方式は驚くほど強力です。インストールは不要、停電しても読めて、他人に任せるのも簡単。ただし規模に弱い。常連客が100人を超えたあたりから問題が始まります。「先月Château Margauxを買われた方は誰だったかな?」—— 台帳を最初から最後までめくる羽目になります。在庫の把握も手作業です。
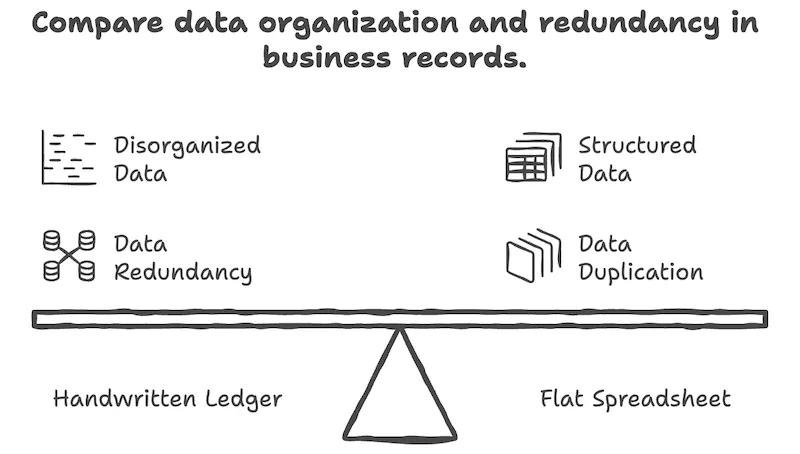
ステージ2:エクセル
店舗が3つに増えます。店主はエクセルを開きます。多くの場合、一枚のシートにすべての取引をひたすら書き下していきます。最も直感的だからです。
売上管理シート(一枚のシートにすべての情報)
| 日付 | 顧客名 | 連絡先 | ワイン名 | 価格 | 数量 |
|---|---|---|---|---|---|
| 2026-04-01 | Alex | alex@example.com | Château Margaux 2020 | 89,000 | 1 |
| 2026-04-02 | Maria | maria@example.com | Pinot Noir Reserve | 45,000 | 2 |
| 2026-04-03 | Alex | alex@example.com | Riesling Kabinett | 32,000 | 1 |
| 2026-04-05 | Alex | alex@example.com | Château Margaux 2020 | 89,000 | 1 |
この方式は最初は楽です。一画面にすべてが見え、フィルター・並び替え・合計もエクセルの基本機能でできます。しばらくはこれで凌げます。
しかし取引が積み重なり始めると、問題が顔を出します。
- 同じ情報が繰り返される。Alexが三回来たなら、名前と連絡先が三回まったく同じように書かれます。同じワインが売れるたび、ワイン名と価格がまた書かれます。
- 一度変えると複数行を直さなければいけない。Alexの連絡先が変わった?過去の取引行をすべて探して一つずつ修正する必要があります。一カ所でも漏らすとデータがもつれます。
- タイプミス一つが別人を生みます。「Alex」と打ったり「alex」と打ったり、次に「Alexander」と書いていたら、後で集計するときには三人に見えます。
- 同時に編集できません。二人が同じファイルをいじると、一方の変更が消えます。
- 三店舗のファイルを誰かが手動でまとめなければなりません。
- オンラインショップ、決済システム、会計ソフトとは自動で繋がりません。
本質的な問題は「同じ情報を複数の場所に繰り返し書いている」ことです。この一つの原因から、上のいろいろな不便が派生します。
ステージ3:データベース
ワインショップがオンラインショップをオープンします。注文は24時間入ってきます。昼間は店舗のPOSから、夜はウェブサイトから、週末は提携レストランから。一枚のシートのエクセルでは物理的に不可能です。
ここからが、データベースが必要になる地点です。
ここで先にお伝えしておくことがあります。これから見せる「注文が自動で積み重なるオンラインショップ」は、実はデータベース単体が生み出す景色ではありません。ウェブサイトを配信するウェブサーバー、システム同士がデータをやり取りするためのAPI、イベントが起きた瞬間に知らせてくれるWebhookなど、複数の道具が一緒に動いて初めて可能になる話です。これらの概念を一度に説明すると、かえって頭が絡まります。ですから今日はその中で「データベースが担う役割」だけを切り取って見ていきます。サーバー、API、Webhookの話はこのシリーズの次回以降で順に扱います。
鍵は「分離」です
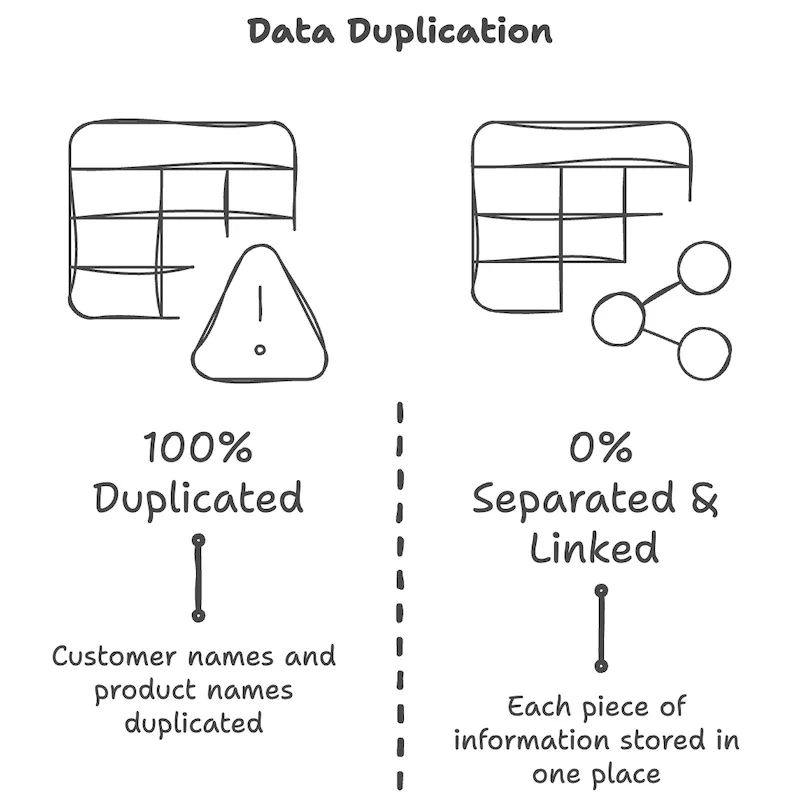
ステージ2で浮かび上がった本当の問題は「同じ情報を複数の場所に繰り返し書くこと」でした。データベースはこの問題に正面から取り組みます。方法はシンプルです。性質の違う情報を別々の表に分け、互いを番号で繋ぐことです。
ワインショップの平らなシートを三つの表に分けてみましょう。
顧客テーブル
| 顧客番号 | 名前 | 連絡先 |
|---|---|---|
| 001 | Alex | alex@example.com |
| 002 | Maria | maria@example.com |
商品テーブル
| 商品番号 | ワイン名 | 価格 |
|---|---|---|
| 101 | Château Margaux 2020 | 89,000 |
| 102 | Pinot Noir Reserve | 45,000 |
| 103 | Riesling Kabinett | 32,000 |
売上テーブル
| 日付 | 顧客番号 | 商品番号 | 数量 |
|---|---|---|---|
| 2026-04-01 | 001 | 101 | 1 |
| 2026-04-02 | 002 | 102 | 2 |
| 2026-04-03 | 001 | 103 | 1 |
| 2026-04-05 | 001 | 101 | 1 |
三つの表を、先ほどの平らなシートと比べてみてください。違いがはっきりしています。
- 名前は顧客テーブルに一度だけ、ワイン名と価格は商品テーブルに一度だけあります。
- 売上テーブルには名前の代わりに番号だけ入ります。
- Alexが4回来ても、「Alex」という文字は顧客テーブルの一行にしか存在しません。
なぜ番号で繋ぐのか?名前や連絡先は変わったり表記にブレが出たりしますが、番号は一度振ると変わらないからです。Alexの連絡先が変わっても、顧客テーブルの一行を直せば、彼の過去と未来の取引を照会するたびに常に最新の情報で繋がって見られます。平らなシートでの「Alexと書かれた全行を探して直す」手間が消えます。
エクセルのシート・見出し・一行だったものが、データベースの世界ではテーブル(Table)・カラム(Column)・レコード(Record、またはRow)と呼ばれます。この三つが基本単位です。用語は変わりますが、見える形は先ほどの表そのままです。
分離された構造の上にシステムが回ります
ここまで見ると「エクセルでもシートを三つに分ければいいだけでは?」と思うかもしれません。その通り、構造自体はエクセルでも真似できます。しかし実際に稼働するサービスになるためには、エクセルでは手に負えないことをデータベースが追加で引き受けてくれます。
さて、オンラインショップが開きました。システムが動いている間、データベースの売上テーブルにはこのように記録が積み重なります。
売上テーブル(自動記録)
| 時刻 | 顧客番号 | 商品番号 | 数量 | チャネル |
|---|---|---|---|---|
| 2026-04-14 10:23:14 | 047 | 101 | 1 | ウェブサイト |
| 2026-04-14 10:23:29 | 112 | 205 | 2 | 店舗POS |
| 2026-04-14 10:23:41 | 089 | 101 | 1 | ウェブサイト |
| 2026-04-14 10:23:55 | 204 | 103 | 3 | レストラン |
平らなシートと違って、人が手で入力していません。ウェブサイト、POS、レストランのシステムがそれぞれ自動で押し込んでいます。1秒に数十件ずつ別々の場所から入ってきても、データベースは揺らがずに受け取ります。
エクセルと比べて、データベースの段階で変わるのは次の四つです。
- 複数のシステムが同時にアクセスします。ウェブサイト、POS、会計ソフトが同じデータをリアルタイムで読み書きします。
- ルールが強制されます。「売上レコードには必ず顧客番号と商品番号が必要」というルールをDB自身が検査します。ルール違反のデータはそもそも入ってきません。
- 素早く検索します。数百万件あっても、インデックス(index、いわゆる索引)を通じて特定の顧客の注文を即座に取り出します。
- 自動でバックアップされます。サーバーが故障しても、データは他のサーバーに複製されています。
エクセルのマスをひとつずつ人が管理していた時代から、分離された構造と自動化されたルールがデータを守る時代へと移ってきたわけです。
エクセルとデータベースを並べて比較
ここまでの話を一枚にまとめるとこうなります。
| 項目 | エクセル | 関係データベース |
|---|---|---|
| 同時編集 | 衝突発生 | 数百〜数千人が同時に可能 |
| データ整合性 | 人が確認 | DBが自動検証 |
| 検索速度 | 行が増えると遅くなる | インデックスで即応答 |
| バックアップ | 手動保存 | 自動複製 |
| 外部システム連携 | 手動エクスポート/インポート | 自動連携可能 |
| 初期コスト | 実質ゼロ | 設定・保守が必要 |
大事なのは「エクセルが悪くてDBが良い」という話ではありません。規模・速度・繋ぐべきシステムの数が変われば、道具も変わるべきだということです。ほとんどの小規模ビジネスはエクセルで始めても問題ありませんし、エクセル段階でデータの流れを掴んでおいた経験は、のちにデータベースへ移行するときそのまま資産になります。
現代のシステムはデータベースをどう使うか
今日私たちが使うほとんどのサービスの裏にはデータベースがあります。オンラインショップの商品一覧、メッセンジャーの会話履歴、決済サービスの取引明細、地図アプリの店舗情報 —— すべてDBに保存されています。見える画面は薄い殻にすぎず、その裏に積み重なったデータこそがビジネスの本当の資産です。
規模のあるサービスでは、DBは一人では働きません。
- 複数台のサーバーに複製され、障害にも耐えます。
- 権限システムを通じて、誰がどのデータを見られるかを制御します。
- 監査ログが残り、誰がいつ何を変えたかを追跡できます。
- 分析用DBにデータをコピーし、売上分析や推薦モデルの学習に使います。
データは台帳ではなく資本です。台帳は閉じれば忘れられますが、資本は積み重なるほど複利で働きます。よく整理されたデータベースは時間が経つほど会社の競争力になります。
関係型のほかに「畳む方式」もあります
ここまで今日見てきたのは関係データベースでした。シート(テーブル)を分けて番号で繋ぎ、重複をなくす方式です。最も古く最も広く使われ、データが数千万件単位に膨らんだときに真価を発揮します。
しかし反対方向のアプローチもあります。販売一件に関する情報(顧客・商品・数量・日付)を三つのシートに分けるのではなく、一塊のJSONブロックにまとめて畳み込んで保存する方式です。この保存方式をドキュメント型(Document)データベースと呼び、MongoDBが最も有名です。
エクセルの三つのシートに散らばっていた販売一件を一つのJSONに畳むと、このような形になります。
{
"sale_date": "2026-04-14",
"customer": { "name": "Alex", "email": "alex@example.com" },
"items": [
{ "name": "Château Margaux 2020", "price": 89000, "quantity": 1 },
{ "name": "Pinot Noir Reserve", "price": 45000, "quantity": 2 }
]
}同じ情報でも、関係型では三か所に散らばっていたものが、ドキュメント型では一塊にまとまっています。今日学んだ関係型の分離が、ドキュメント型ではネスト(nesting、入れ子)として現れると理解してください。
倉庫の整理と宅配の箱
二つのアプローチの違いを例えるとこうなります。
関係型は大きな倉庫を種類別に整理しておく方式です。顧客棚、商品棚、売上記録棚がそれぞれあり、注文が入れば複数の棚から必要なものを取り出して組み立てます。物が数万種類を超えても倉庫は揺らぎません。
ドキュメント型は宅配の箱に近いです。注文一件に必要なもの(顧客情報、商品一覧、数量、日付)を箱一つに詰めてそのまま受け渡します。受け取る側は箱を開ければ、その注文に関するすべてを一目で見られます。
どちらが良い悪いではなく、場面に合った道具が違うだけです。倉庫の整理は規模が大きくなったときに力を発揮し、宅配の箱は始めるのが速く、個別の注文を扱うのに楽です。
小さく始めるときにドキュメント型が有利な理由
小さなチームが関係型よりドキュメント型を先に検討する理由は三つあります。
- 始めるのが速い。テーブルや関係をあらかじめ設計しなくても、JSONを一塊送れば保存されます。開発者のいない小さなチームにとって「今日始めて今日動く」は決定的です。
- 初期のビジネスには複雑な関係が不要。関係型の強みは、データが数千万件積み重なり、複数のシステムが複雑に絡み合うときに発揮されます。一日に数十件、店舗一〜二軒の段階では「注文一件に必要な情報を一塊にまとめる」方がむしろシンプルで、ミスも少ないです。
- イベント(event)と自然に合う。注文一件はもともと「顧客一人 + 複数の商品 + 日付」が結ばれた一つのイベントです。これを三つのシートに散らして番号で再び繋ぐより、イベント一つを一塊にまとめる方が、人の直感に近いです。
3Min APIがドキュメント型をデフォルトに選んだ背景もこの三つです。もちろん時間が経ち、関係型ならではの機能 —— 複数のテーブルをまとめて一度に照会するような —— が必要になる瞬間も来ます。そのために関係型の機能もロードマップに入っています。ただし今の出発点は「動き始めるまでの時間を短くすること」です。
今日すぐ試せること
ここまで読んでくださったなら、データベースの内部の動きや具体的な設計方法を必ずしも知る必要はありません。この記事の目的はただ一つ、「自分のビジネスのデータを頭の中ではなく、表として整理する感覚」をつかむことでした。その感覚はエクセルだけでも十分に鍛えられます。
下の三つのステップを順にやってみてください。全部エクセルの中で完結します。
Action 1. エクセル三枚でビジネスを描く
今ビジネスのデータをエクセル一枚のシートに詰め込んでいらっしゃるなら、新しいファイルを一つ開いてシートを三つに分けてみてください。それぞれが人、物、取引にあたるデータです。業種が何であれ、ほとんどのビジネスはこの三つの軸で表現できます。先ほど見たワインショップの表を参考に、実際のデータを5〜10行だけ埋めてみてください。ルールは一つ、同じ情報は一か所にだけ書くことです。人の名前は人シートだけ、商品名は物シートだけ、取引シートには番号だけを書きます。
Action 2. AIにエクセルの整理について助言をもらう
埋めたファイルをChatGPT、Claude、Geminiのいずれかで開いてアップロードし、こう聞いてみてください。
添付したスプレッドシートは私の[業種]ビジネスのデータです。このエクセルをよりよく管理するには、シートと列をどのように分けるのが良いでしょうか?同じ情報が複数の場所に重複しないようにする観点で、非開発者でも実践できるレベルで助言してください。
ここでAIが返してくる答えは「データベース設計図」ではなく「より整理されたエクセルの構造」であるべきです。それで十分です。この過程を一度くぐれば、データを構造化するというのがどんな感覚なのか、体でわかるようになります。
Action 3. 自動化の方向を描いてみる
エクセルの構造が整ったら、最後は「このデータをいつか自動で集めなければならなくなったらどうするか」です。開発者になる必要はありません。方向だけ掴めば十分です。
同じAIの会話ウィンドウに、下のプロンプトをそのままコピーして貼り付けてください。
次のサービスドキュメントを参考にして、先ほど整理したエクセルの構造を、あとでこのサービスで自動収集するにはどの順序で始めるのが良いか、非開発者が理解できる言葉で段階的に教えてください。
https://3minapi.com/llms-full.txtAIが返してくる答えは、おそらく先ほどの宅配の箱の例えそのまま、「エンドポイント一つを作って、注文一件をJSONブロック一つで送ればよい」という方向になるはずです。そのような答えが出ても慌てないでください —— 今日学んだ関係型の「分離」構造が、ドキュメント型では「畳む(ネスト)」に変わって現れるだけです。
AIが皆さんのビジネス状況に合わせて最初の一歩を案内してくれます。その答えを手に、準備ができたときに開発者なしでエンドポイントを作る方法をたどればよいのです。
次のピースへ
今日は「データを入れる器」であるデータベースを見てきました。器が一つあれば十分に思えるかもしれませんが、実際のビジネスでは器にデータが自動で積み重なり、複数のシステムが同時に同じ器を見なければなりません。それを可能にする「窓口」が次のテーマです。
次回はその窓口、つまりAPIを扱います。ワインショップ店主のオンラインショップが、POSやウェブサイト、提携レストランとどのように同じデータをやり取りするのか、引き続き追っていきましょう。
Related Posts
JSONとは?非開発者の店主のための入門ガイド
ワインショップ店主の物語を締めくくるJSON入門ガイド。Excelシートを出発点に、キー・値・オブジェクト・配列という再帰構造をたどり、今日そのまま自分のビジネスの注文をJSONで書いてみる実習まで、事前知識なしで読める形に整理しました。
APIとは?非開発者の店主のための入門ガイド
ワインショップ店主の物語でつなぐAPI入門ガイド。APIがなぜ「安全な通路」なのか、なぜ自分で作るのが大変なのか、今日何を試せるのかを、前提知識なしでたどれるようにまとめました。
小規模ビジネスのAI準備 — データ、API、そして今やるべきこと
AIが得意なことと苦手なこと、そして小規模ビジネスが必ず準備すべき2つのこと — データとAPIに関する実用ガイドです。