什麼是資料庫?Excel 使用者的入門指南

大家好,我是 yeonghyeon,負責 3Min API 的開發。
在過去的文章裡,Chae-won 和我都多次提到「資料庫」這個詞。講 Webhook 時提過,講 JSON 和結構時提過,講 AI 時代的資料準備 時也提過。從來沒有缺席。
但我們從未專門寫一篇文章來回答「資料庫到底是什麼」這個問題。今天就把它講清楚。這是後面將延伸到 API 與 JSON 的系列裡的第一塊拼圖。
📚 寫給非開發者的資料基礎三部曲
- 資料庫 —— 裝資料的容器(本文)
- API —— 安全進出的窗口
- JSON —— 往來訊息的形狀
這篇文章只有一個目的。在深入學習「資料庫」這個詞背後的複雜技術之前,先建立 「把自己業務的資料從腦袋裡攤到眼前的表格來整理」 的感覺。只要這份感覺有了,剩下的東西在需要時會自然跟上。所以您不需要任何先備知識。若您知道 Excel 是「把資料以表格形式整理的工具」就更順手,即使沒有,我們也會在本文中一起看,請輕鬆閱讀。
什麼是資料庫
先從字典定義開始。維基百科 把資料庫描述為「有組織地整理的資料集合」。在技術用語裡,把這些資料存起來、管理並可以檢索的系統叫做 DBMS(DataBase Management System),但在日常說法裡,我們會把兩者合稱為「資料庫(DB)」。
用一句話概括:
資料庫 = 用來結構化地儲存資料、快速查找,並讓多人同時使用的系統。
不需要硬背這段定義。事實上,您每天已經在用好幾種「資料庫」了。
日常生活中的資料庫
請想想下列三樣東西。
- 通訊錄:姓名、電話、地址一列列整齊排著。找到某個名字,號碼就立刻出來。
- 圖書館的借書卡:每本書都有一張卡,記錄誰在什麼時候借走。借出時寫上,歸還時擦掉。
- 便利商店的庫存帳簿:記錄商品名、數量、入庫日。賣出就減,進貨就加。
看出這三者的共通點了嗎?都有 固定的格式、相同形狀的資料反覆累積、需要時可以迅速查到。這就是資料庫的本質。無論工具是紙、Excel 還是專用伺服器,工具在變,原理不變。
資料庫的種類
現代資料庫依用途分成幾種。簡單過一遍:
- 關聯式資料庫(Relational、RDB):使用最廣、歷史最長的方式。資料像 Excel 一樣以「表格」形式儲存,表與表之間透過關聯連結。MySQL、PostgreSQL、Oracle 都屬於這一類。
- 文件式資料庫(Document):不是表格,而是把 JSON 這樣的文件整塊存起來。適合結構經常變化的資料。MongoDB 是代表。
- 圖形資料庫(Graph):把人與人、物與物之間的「關聯」本身放在中心。適合社群網路和推薦引擎。
- 向量資料庫(Vector):在 AI 時代興起的方式。把文字或圖片存成數字陣列,用來快速找到「含義相近」的內容。
今天這篇文章聚焦其中使用最廣、商業現場最基礎的 關聯式資料庫。
葡萄酒店店主的故事
光靠理論不容易懂。跟著實際情境走一遍會更快。
想像您開了一間小葡萄酒店。一開始只有一家店,一天只有幾位客人。隨著生意變大,管理資料的方式也跟著長大。
階段 1:手寫帳本
剛開業時一本筆記本就夠了。日期、客人姓名、葡萄酒名、金額 —— 把這四樣每天寫下來。今天五位客人就五行,十位就十行。
這種方式出乎意料地強大。不用安裝,停電也能讀,交給別人也容易。但 規模一大就吃力。常客超過一百人以後,麻煩開始了。「上個月買過 Château Margaux 的是哪一位?」—— 得把帳本從頭翻到尾。庫存盤點也全靠手工。
階段 2:Excel
門市開到了三家。店主打開了 Excel。大多數情況下,就是把所有交易一股腦兒寫在同一張表上。這最直觀。
銷售管理表(一張表裡包含所有資訊)
| 日期 | 顧客姓名 | 聯絡方式 | 葡萄酒名 | 價格 | 數量 |
|---|---|---|---|---|---|
| 2026-04-01 | Alex | alex@example.com | Château Margaux 2020 | 89,000 | 1 |
| 2026-04-02 | Maria | maria@example.com | Pinot Noir Reserve | 45,000 | 2 |
| 2026-04-03 | Alex | alex@example.com | Riesling Kabinett | 32,000 | 1 |
| 2026-04-05 | Alex | alex@example.com | Château Margaux 2020 | 89,000 | 1 |
一開始這種方式很舒服。所有內容都在一個螢幕上,Excel 內建的篩選、排序、加總也夠用。靠這個撐一段時間不成問題。
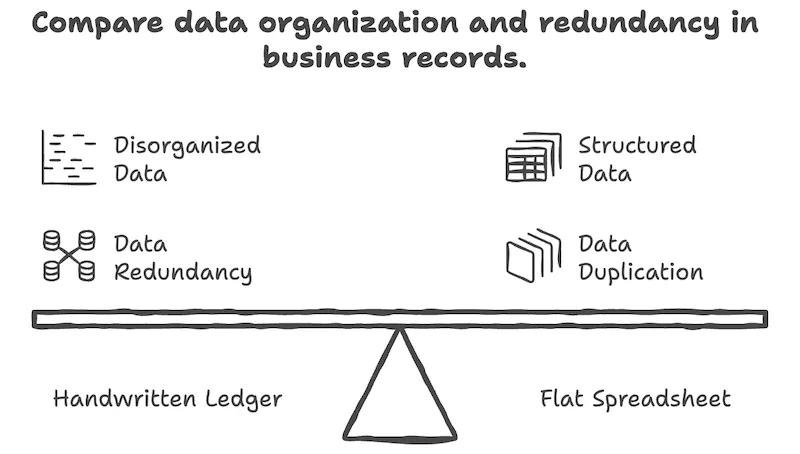
但隨著交易累積,問題就浮現了。
- 相同資訊反覆出現。Alex 來過三次,他的姓名和聯絡方式就被原樣寫了三次。同一款酒每次賣出時,酒名與價格又寫一次。
- 改一次要改好幾列。Alex 的聯絡方式變了?就得把過去每一筆交易找出來一筆一筆改。漏掉一列,資料就亂了。
- 一個錯字就變成另一個人。有時打成「Alex」,有時打成「alex」,再有時寫成「Alexander」,彙整時看起來就像三個人。
- 無法同時編輯。兩人同時改同一個檔案,其中一方的修改會不見。
- 三家門市的檔案得有人手工合併。
- 無法自動與線上商店、金流系統、財務軟體對接。
核心問題是 「把同一條資訊寫在多個地方」。上面那些麻煩都是由這一個原因衍生出來的。
階段 3:資料庫
葡萄酒店開了線上商店。訂單 24 小時不斷湧入。白天從門市 POS 進來,晚上從網站進來,週末從合作餐廳進來。一張表的 Excel 在物理上不可能應付。
從這個時刻起,就需要資料庫了。
先說一件事。接下來要描繪的「訂單自動堆積的線上商店」其實 並不是資料庫一個人造出來的景象。託管網站的 Web 伺服器、讓系統之間交換資料的 API、事件發生時立即通知的 Webhook —— 這些工具必須一起運作才成立。一次把這些概念全部講完,反而會讓腦袋打結。所以今天只 把「資料庫負責的那部分」單獨拉出來看。伺服器、API、Webhook 的故事會在本系列後續文章裡依序講。
關鍵是「分離」
階段 2 暴露出來的真正問題是「把同一條資訊寫在多個地方」。資料庫正面解決這個問題。方法很單純:把性質不同的資訊拆到不同的表裡,再用編號把它們彼此連起來。
把葡萄酒店那張扁平表拆成三張表看看。
顧客表
| 顧客編號 | 姓名 | 聯絡方式 |
|---|---|---|
| 001 | Alex | alex@example.com |
| 002 | Maria | maria@example.com |
商品表
| 商品編號 | 葡萄酒名 | 價格 |
|---|---|---|
| 101 | Château Margaux 2020 | 89,000 |
| 102 | Pinot Noir Reserve | 45,000 |
| 103 | Riesling Kabinett | 32,000 |
銷售表
| 日期 | 顧客編號 | 商品編號 | 數量 |
|---|---|---|---|
| 2026-04-01 | 001 | 101 | 1 |
| 2026-04-02 | 002 | 102 | 2 |
| 2026-04-03 | 001 | 103 | 1 |
| 2026-04-05 | 001 | 101 | 1 |
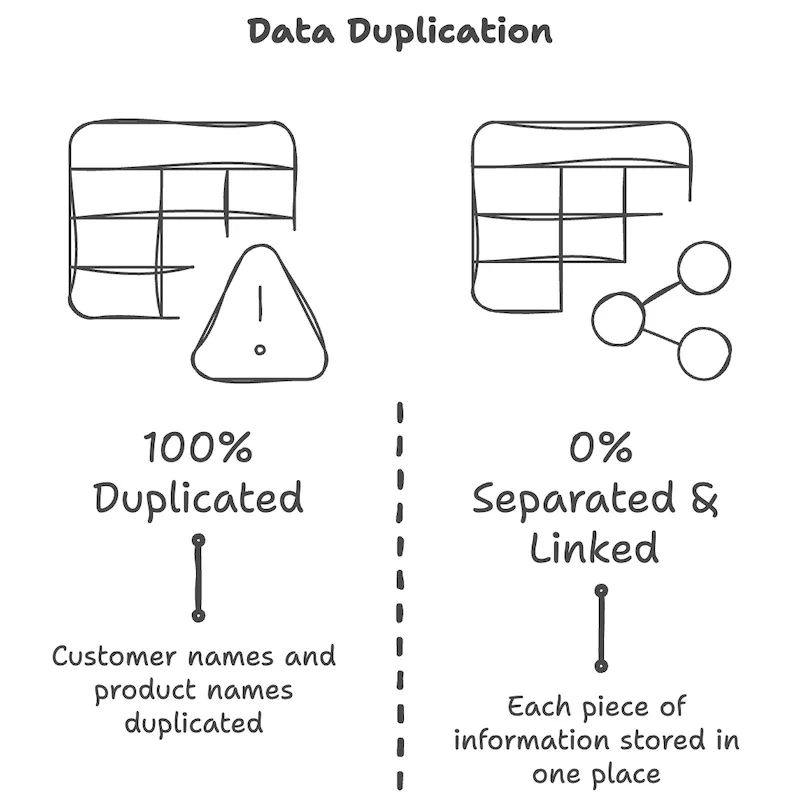
把這三張表和前面的扁平表對比一下,差別很明顯。
- 姓名只在顧客表裡出現一次,葡萄酒名與價格只在商品表裡出現一次。
- 銷售表裡用 編號 代替姓名。
- 就算 Alex 來過四次,「Alex」這幾個字也只存在於顧客表的一列裡。
為什麼用編號連起來?因為姓名或聯絡方式可能改變,寫法也可能不一樣,但 編號一旦指定就不會變。Alex 的聯絡方式變了,只要改顧客表裡的一列,日後不論查他過去或未來的交易,都會接上最新的資訊。扁平表上那種「把寫著 Alex 的所有列都找出來改一遍」的辛苦就不見了。
Excel 裡原本叫 工作表 · 欄位標頭 · 一列 的東西,在資料庫的世界裡分別叫做 資料表(Table)· 欄(Column)· 記錄(Record 或 Row)。這三個是基本單位。用詞換了,但看到的形狀和剛才那些表一樣。
分離的結構之上才真正跑起系統
看到這裡您可能會想:「那我在 Excel 裡也把工作表分成三張不就行了?」沒錯,結構本身 Excel 也能模仿。但要讓它成為真正運轉的服務,還有一些 Excel 應付不了的事,資料庫會額外承擔。
好,線上商店已經開張。系統運作期間,資料庫的銷售表裡會像這樣不斷累積紀錄。
銷售表(自動記錄)
| 時間 | 顧客編號 | 商品編號 | 數量 | 通路 |
|---|---|---|---|---|
| 2026-04-14 10:23:14 | 047 | 101 | 1 | 網站 |
| 2026-04-14 10:23:29 | 112 | 205 | 2 | 門市 POS |
| 2026-04-14 10:23:41 | 089 | 101 | 1 | 網站 |
| 2026-04-14 10:23:55 | 204 | 103 | 3 | 餐廳 |
和扁平表不同,沒有人在手動打字。網站、POS、餐廳的系統各自往裡推資料。即使一秒鐘有幾十筆從不同地方湧進來,資料庫也能穩穩地收下。
與 Excel 相比,資料庫階段會改變的事有以下四件:
- 多個系統同時存取。網站、POS、財務軟體即時讀寫同一份資料。
- 強制執行規則。像「銷售紀錄必須要有顧客編號與商品編號」這樣的規則由資料庫自己檢查。不符合規則的資料根本進不來。
- 查得快。即便資料多達數百萬筆,透過索引(index,類似目錄)也能立即找到某位顧客的訂單。
- 自動備份。就算伺服器故障,資料也已經複製到其他伺服器上。
從一個一個由人去管理 Excel 儲存格的年代,我們來到了一個靠 分離的結構與自動化規則 來守護資料的年代。
把 Excel 和資料庫並排比較
到這裡為止的內容,一張表就能整理:
| 項目 | Excel | 關聯式資料庫 |
|---|---|---|
| 同時編輯 | 會衝突 | 數百至數千人可同時 |
| 資料完整性 | 靠人工核對 | 資料庫自動檢查 |
| 搜尋速度 | 列多了就會變慢 | 透過索引即時回應 |
| 備份 | 手動儲存 | 自動複製 |
| 外部系統串接 | 手動匯出/匯入 | 可自動連接 |
| 初期成本 | 幾乎為零 | 需要設定與維護 |
重點不是 「Excel 不好,資料庫好」。而是:當您的規模、速度、要連接的系統數量改變時,工具也該跟著改變。大多數小型生意完全可以從 Excel 開始,而在 Excel 階段掌握資料流的經驗,之後遷移到資料庫時,會原封不動地成為資產。
現代系統怎麼使用資料庫
今天我們使用的幾乎所有服務背後都有一個資料庫。線上商店的商品清單、即時通訊的對話記錄、金流服務的交易明細、地圖應用裡的店家資訊 —— 全都存在資料庫裡。看得到的畫面只是一層薄薄的外殼,背後累積的資料才是業務真正的資產。
在具規模的服務裡,資料庫不是一個人在工作。
- 資料會 複製到多台伺服器,即使發生故障也撐得住。
- 透過 權限系統 控制誰可以看哪些資料。
- 稽核日誌 可以追蹤誰在什麼時候改了什麼。
- 資料會複製到 分析用資料庫,用於銷售分析、推薦模型訓練等。
資料不是帳本,而是 資本。帳本闔上就容易被遺忘,而資本愈累積愈會產生複利。整理得宜的資料庫,隨著時間會成為公司的競爭力。
關聯式之外還有「折疊式」
今天我們看到的是 關聯式 資料庫。把工作表(資料表)拆開、用編號連接,消除重複。它是最老牌也最常用的方式,在資料達到數千萬筆等級時才真正顯出威力。
但也有相反方向的做法。不把一次銷售的資訊(顧客、商品、數量、日期)拆成三張表,而是 把整塊資訊折疊進一個 JSON 區塊裡一起存。這種儲存方式叫做 文件式(Document) 資料庫,MongoDB 最為知名。
把散落在 Excel 三張表裡的一次銷售折疊進一個 JSON,形狀像這樣:
{
"sale_date": "2026-04-14",
"customer": { "name": "Alex", "email": "alex@example.com" },
"items": [
{ "name": "Château Margaux 2020", "price": 89000, "quantity": 1 },
{ "name": "Pinot Noir Reserve", "price": 45000, "quantity": 2 }
]
}同樣的資訊,在關聯式裡散落在三處,在文件式裡則 被打包進同一塊。今天學到的關聯式的 分離,在文件式裡以 巢狀(nesting) 的形式出現 —— 可以這樣理解。
整理的倉庫與宅配箱
把兩種做法打個比方:
關聯式 就像一個 依種類整理好的大倉庫。有顧客貨架、商品貨架、銷售紀錄貨架,訂單進來時從各個貨架取出需要的東西組合起來。就算貨物種類超過數萬,倉庫依然穩如泰山。
文件式 則比較像 宅配箱。把一筆訂單需要的所有東西(顧客資訊、商品清單、數量、日期)裝進同一個箱子,就這樣原封不動地送出去。收到的一方打開箱子,就能一眼看到這筆訂單的全部內容。
沒有哪一種絕對比較好,而是 適合不同的情境。倉庫整理在規模變大時發揮威力,宅配箱則啟動得快,處理個別訂單也更方便。
小規模起步時文件式的優勢在哪裡
小團隊會先考慮文件式而不是關聯式,原因主要有三個:
- 上手快。不用事先設計好資料表與關聯,送一塊 JSON 過去就存好了。對沒有開發者的小團隊來說,「今天開始,今天就能跑」是決定性的。
- 初期業務不需要複雜的關聯。關聯式的強項要在資料堆到數千萬筆、多個系統錯綜交織時才顯現出來。在「一天數十筆、一兩家店」的階段,「把一筆訂單需要的資訊打包在一起」反而更單純,也更不容易出錯。
- 和事件(event)自然契合。一筆訂單本來就是「一位顧客 + 數個商品 + 日期」綁在一起的一個事件。把它拆到三張表再用編號連回去,不如把一個事件整塊打包,更貼近人的直覺。
3Min API 會預設選擇文件式,背景也是這三點。當然,隨著時間推移,關聯式特有的功能 —— 像是把多張表合起來一次查詢 —— 也會成為剛需。為此,關聯式功能也已經排入產品藍圖。但現在的出發點,是「縮短跑起來之前的時間」。
今天就能試試的事
讀到這裡,其實您不必非得了解資料庫內部的運作機制,也不必掌握具體的設計方法。這篇文章只有一個目的:讓您建立 「把自己業務的資料從腦袋裡攤到眼前的表格來整理」 的感覺。這種感覺只靠 Excel 就能充分鍛鍊。
請依序試下列三個步驟,全部都在 Excel 裡完成。
行動 1. 用三張 Excel 工作表描繪您的業務
如果您現在把業務資料全部塞在一張 Excel 表裡,請打開一個新檔案,把它分成三張工作表。它們分別對應 人、物、交易。不管您的行業是什麼,大部分業務都能用這三個面向來表達。參考上面葡萄酒店的範例表,填 5–10 列真實資料就好。規則只有一條:同一條資訊只寫在一個地方。人的姓名只寫在「人」表裡,商品名只寫在「物」表裡,「交易」表只寫編號。
行動 2. 請 AI 幫您看 Excel 結構
把填好的檔案在 ChatGPT、Claude、Gemini 中任選一個開啟並上傳,然後這樣問:
附件的試算表是我 [行業] 業務的資料。為了更好地管理這份 Excel,應該怎麼劃分工作表與欄位?請從「避免同一條資訊在多處重複」的角度,給我一份非開發者也能實際執行的建議。
AI 這裡回來的應該是「更整齊的 Excel 結構」,而不是「資料庫設計圖」。這樣就夠了。走過這個流程一次,您就會用身體記住「把資料結構化」是什麼感覺。
行動 3. 勾勒自動化的方向
Excel 結構整理好以後,最後一步是:「將來哪天要把這些資料自動收集起來,要從哪裡開始?」您不需要成為開發者。只要把方向定下來就好。
在同一個 AI 對話視窗,把下面這段提示詞整段複製貼上:
請參考下面這份服務文件,告訴我應該依什麼樣的順序開始,才能把我剛才整理好的 Excel 結構,日後用這項服務自動收集。請用非開發者也能理解的語言,一步一步說明。
https://3minapi.com/llms-full.txtAI 給您的回答,多半會沿著前面那個宅配箱比喻的方向,也就是:「建立一個端點,把一筆訂單以一個 JSON 區塊送出就好。」 如果它這麼回答,請不必意外 —— 那正是我們今天學到的關聯式的「分離」結構,在文件式裡換了個樣子,變成了「折疊(巢狀)」。
AI 會根據您實際的業務情境引導您的第一步。拿到那份回答之後,等您準備好,可以照著 沒有開發者也能建立端點的方法 一步一步走下去。
下一期
今天我們看了「裝資料的容器」—— 資料庫。光有一個容器好像就夠了,但在真實業務裡資料會自動堆到容器裡,多個系統必須同時看著同一個容器。讓這件事成立的「窗口」就是下一個主題。
下一期我們要講的就是這個窗口,也就是 API。請繼續跟著葡萄酒店店主,看他的線上商店、POS 與合作餐廳之間是怎麼互相交換同一份資料的。
→ 下一期:什麼是 API?寫給非開發者店主的入門指南
Related Posts
什麼是 JSON?寫給非開發者店主的入門指南
一份為葡萄酒店店主故事收尾的 JSON 入門指南。從一張 Excel 表出發,沿著鍵、值、物件、陣列的遞迴結構走一遍,最後還帶一個「今天就能動手」的練習:把自己生意裡的一樁事寫成 JSON。無需任何前置知識。
什麼是 API?寫給非開發者店主的入門指南
用葡萄酒店店主的故事延續的 API 入門指南。講清楚 API 為什麼是「安全的通道」、為什麼自己打造很不容易、今天又能動手試什麼,讓沒有任何基礎的讀者也能跟上。
中小企業的 AI 準備——資料、API,以及現在該做的事
AI 擅長什麼、不擅長什麼,以及中小企業必須準備的兩件事——資料與 API 的實用指南。