什么是数据库?Excel 用户的入门指南

您好,我是 yeonghyeon,负责 3Min API 的开发。
在之前的文章里,Chae-won 和我都反复提到过"数据库"这个词。讲 Webhook 时提到过,讲 JSON 和架构时提到过,讲 AI 时代的数据准备 时也提到过。从来没有缺席过。
但我们从未专门用一篇文章来回答"数据库到底是什么"这个问题。今天就把它讲透。这是后面将延伸到 API 和 JSON 的系列里的第一块拼图。
📚 写给非开发者的数据基础三部曲
- 数据库 —— 装数据的容器(本文)
- API —— 安全进出的窗口
- JSON —— 往来消息的形状
本文只有一个目标。在深入学习"数据库"这个词背后的复杂技术之前,先建立起 "把自己业务的数据从脑子里摊到面前的表格中整理" 的感觉。只要这份感觉有了,剩下的东西在需要时会自然跟上。所以您不需要任何基础知识。如果知道 Excel 是"把数据以表格形式整理的工具"就更顺手,即使没有,我们也会在正文里一起看,请轻松地读下去。
什么是数据库
先从词典定义开始。维基百科 把数据库描述为"有组织地整理的数据集合"。在技术术语里,把这些数据加以存储、管理并能够检索的系统叫作 DBMS(DataBase Management System),但在日常说法里,我们会把这两者合起来称为"数据库(DB)"。
用一句话概括:
数据库 = 一个用来结构化地存储数据、快速查找,并允许多人同时使用的系统。
不用硬背这段定义。事实上,您每天已经在使用好几种"数据库"了。
日常生活中的数据库
请想想下面这三样东西。
- 通讯录:姓名、电话、地址一行行整齐排列。找到一个名字,电话就立刻出来了。
- 图书馆的借书卡:每本书都有一张卡,记录谁在什么时候借走。借出时写上,归还时擦掉。
- 便利店的库存账本:记录商品名、数量、入库日期。卖出就减,进货就加。
看出这三者的共通点了吗?都有 固定的格式,相同形状的数据反复累积,需要时可以迅速查到。这就是数据库的本质。无论工具是纸、Excel 还是专用服务器,工具在变,原理不变。
数据库的种类
现代数据库按用途分成几种。简单过一遍:
- 关系型数据库(Relational、RDB):使用最广泛、历史最长的方式。数据像 Excel 一样以"表格"形式存储,表与表之间通过关系连接。MySQL、PostgreSQL、Oracle 都属于这一类。
- 文档型数据库(Document):不是表格,而是把 JSON 这样的文档整块存起来。适合结构经常变化的数据。MongoDB 是代表。
- 图数据库(Graph):把人与人、物与物之间的"关系"本身放在中心。适合社交网络和推荐引擎。
- 向量数据库(Vector):在 AI 时代兴起的方式。把文字或图片存成数字数组,用来快速找到"含义相近"的内容。
今天这篇文章聚焦其中使用最广、业务现场最基础的 关系型数据库。
葡萄酒店店主的故事
光靠理论不容易理解。跟着实际场景走一遍会更快。
想象您开了一家小葡萄酒店。一开始只有一家店,一天只有几位客人。随着生意变大,管理数据的方式也跟着成长。
阶段 1:手写账本
刚开业时一本笔记本就够了。日期、客人姓名、葡萄酒名、金额 —— 把这四样每天写下来。今天五位客人就五行,十位就十行。
这种方式出奇地强大。不用安装,停电也能读,交给别人也容易。但 规模一大就吃力。常客超过一百人以后,麻烦开始了。"上个月买过 Château Margaux 的是哪位?"—— 得把账本从头翻到尾。库存盘点也全靠手工。
阶段 2:Excel
门店开到了三家。店主打开了 Excel。大多数情况下,就是把所有交易一股脑儿写在同一张表上。这最直观。
销售管理表(一张表里包含所有信息)
| 日期 | 客户姓名 | 联系方式 | 葡萄酒名 | 价格 | 数量 |
|---|---|---|---|---|---|
| 2026-04-01 | Alex | alex@example.com | Château Margaux 2020 | 89,000 | 1 |
| 2026-04-02 | Maria | maria@example.com | Pinot Noir Reserve | 45,000 | 2 |
| 2026-04-03 | Alex | alex@example.com | Riesling Kabinett | 32,000 | 1 |
| 2026-04-05 | Alex | alex@example.com | Château Margaux 2020 | 89,000 | 1 |
一开始这种方式很舒服。所有内容在一个屏幕上,Excel 自带的筛选、排序、求和也够用。靠这个维持一段时间不成问题。
但随着交易累积,问题就露出来了。
- 相同信息反复出现。Alex 来过三次,他的姓名和联系方式就被原样写了三次。同一款酒每次卖出时,酒名和价格又写一遍。
- 改一次要改好几行。Alex 的联系方式变了?就得找到过去每一笔交易一个一个地改。漏掉一行,数据就错乱了。
- 一个错字就变成另一个人。有时打成"Alex",有时打成"alex",再有时写成"Alexander",到汇总时看起来就像三个人。
- 不能同时编辑。两个人同时改同一个文件,其中一方的修改会消失。
- 三家门店的文件得有人手工合并。
- 无法自动对接线上商店、支付系统、财务软件。
核心问题是 "把同一条信息写在了多个地方"。上面那些麻烦都是由这一个原因派生出来的。
阶段 3:数据库
葡萄酒店开了线上商店。订单 24 小时不断涌入。白天从门店 POS 进来,晚上从网站进来,周末从合作餐厅进来。一张表的 Excel 物理上不可能承担。
从这个时刻起,就需要数据库了。
先说一件事。接下来要描绘的"订单自动堆积的线上商店"其实 并不是数据库一个人造出来的景象。托管网站的 Web 服务器、让系统之间交换数据的 API、事件发生时立即通知的 Webhook —— 这些工具必须一起工作才成立。一次性把这些概念都讲完反而会让脑子打结。所以今天只 把"数据库负责的那部分"单独拎出来看。服务器、API、Webhook 的故事会在本系列后面的文章里依次讲。
关键是"分离"
阶段 2 暴露出来的真正问题是"把同一条信息写在多个地方"。数据库正面解决这个问题。方法很简单:把不同性质的信息拆到不同的表里,再用编号把它们互相连起来。
把葡萄酒店那张扁平表拆成三张表看看。
客户表
| 客户编号 | 姓名 | 联系方式 |
|---|---|---|
| 001 | Alex | alex@example.com |
| 002 | Maria | maria@example.com |
商品表
| 商品编号 | 葡萄酒名 | 价格 |
|---|---|---|
| 101 | Château Margaux 2020 | 89,000 |
| 102 | Pinot Noir Reserve | 45,000 |
| 103 | Riesling Kabinett | 32,000 |
销售表
| 日期 | 客户编号 | 商品编号 | 数量 |
|---|---|---|---|
| 2026-04-01 | 001 | 101 | 1 |
| 2026-04-02 | 002 | 102 | 2 |
| 2026-04-03 | 001 | 103 | 1 |
| 2026-04-05 | 001 | 101 | 1 |
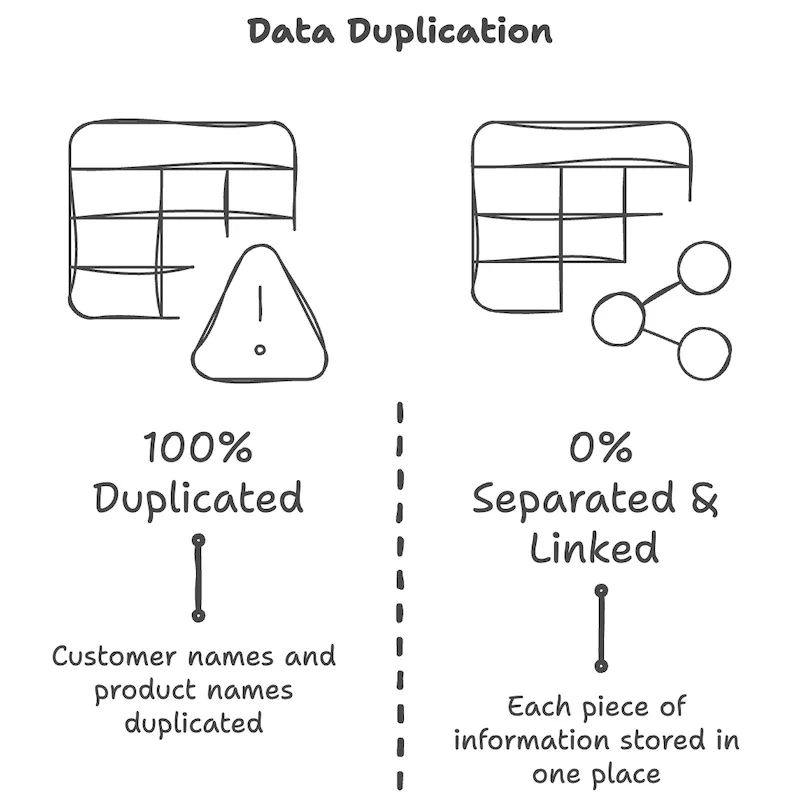
把这三张表和前面的扁平表对比一下,差别很明显。
- 姓名只在客户表里出现一次,葡萄酒名和价格只在商品表里出现一次。
- 销售表里用 编号 代替姓名。
- 即使 Alex 来过四次,"Alex"这几个字也只在客户表的一行里存在。
为什么用编号来连接?因为姓名或联系方式会变,写法也可能不一样,但 编号一旦分配就不会变。Alex 的联系方式变了,只要改客户表里的一行,未来无论怎么查他过去和以后的交易,都会接上最新的信息。扁平表上那种"把写着 Alex 的所有行都找出来改一遍"的辛苦就消失了。
Excel 里原本叫 工作表 · 表头 · 一行 的东西,在数据库世界里分别叫 表(Table)· 列(Column)· 记录(Record 或 Row)。这三者是基本单位。术语变了,但看到的东西和刚才的那些表一样。
分离结构之上才真正跑起系统
看到这里您可能会想:"那我在 Excel 里也把工作表分成三张不就行了?"确实,结构本身 Excel 也能模仿。但要让它成为真正运转的服务,还有一些 Excel 处理不了的事,数据库会额外承担。
好,线上商店已经开张。系统运行时,数据库的销售表里会这样不停地累积记录。
销售表(自动记录)
| 时间 | 客户编号 | 商品编号 | 数量 | 渠道 |
|---|---|---|---|---|
| 2026-04-14 10:23:14 | 047 | 101 | 1 | 网站 |
| 2026-04-14 10:23:29 | 112 | 205 | 2 | 门店 POS |
| 2026-04-14 10:23:41 | 089 | 101 | 1 | 网站 |
| 2026-04-14 10:23:55 | 204 | 103 | 3 | 餐厅 |
和扁平表不同,没有人在手动输入。网站、POS、餐厅的系统各自在往里推数据。即使一秒钟有几十条从不同地方涌进来,数据库也能稳稳地收下。
和 Excel 相比,数据库阶段会变的有以下四件事:
- 多个系统同时访问。网站、POS、财务软件实时读写同一份数据。
- 强制执行规则。像"销售记录必须包含客户编号和商品编号"这样的规则由数据库自己检查。不符合规则的数据根本进不来。
- 查得快。即便有几百万条数据,借助索引(index,相当于目录),也能立刻找到某位客户的订单。
- 自动备份。即便服务器出故障,数据也已经复制到其他服务器上。
从一个一个由人去管 Excel 单元格的年代,我们来到了一个靠 分离的结构与自动化规则 来守护数据的年代。
把 Excel 和数据库放在一起对比
到这里为止的内容,一张表就能总结:
| 项目 | Excel | 关系型数据库 |
|---|---|---|
| 同时编辑 | 冲突 | 数百至数千人同时可用 |
| 数据完整性 | 依赖人工核对 | 数据库自动校验 |
| 搜索速度 | 行多了就变慢 | 通过索引即时响应 |
| 备份 | 手动保存 | 自动复制 |
| 外部系统对接 | 手动导入/导出 | 可自动连接 |
| 初期成本 | 几乎为零 | 需要配置和维护 |
关键不是 "Excel 不好,数据库好"。而是:当您的规模、速度、需要连接的系统数量发生变化时,工具也应当随之变化。大多数小型生意完全可以从 Excel 开始,在 Excel 阶段把握住数据流向的经验,将来迁移到数据库时会原封不动地变成资产。
现代系统是怎么用数据库的
今天我们使用的几乎所有服务背后都有一个数据库。线上商店的商品目录、即时通讯的对话记录、支付服务的交易明细、地图应用里的门店信息 —— 全都存在数据库里。看得到的屏幕只是一层薄薄的壳,背后积累的数据才是业务真正的资产。
在具备一定规模的服务里,数据库并不是一个人在工作。
- 数据会 复制到多台服务器,能够抵御故障。
- 通过 权限系统 控制谁能看到哪些数据。
- 审计日志 可以追踪谁在什么时候改了什么。
- 数据会复制到 分析用数据库,用于销售分析、推荐模型训练等。
数据不是账本,而是 资本。账本合上就容易被忘记,而资本积累得越多越能产生复利。一个整理得好的数据库,时间越久越会成为公司的竞争力。
关系型之外还有"折叠式"
今天我们看到的是 关系型 数据库。把工作表(表格)拆开,用编号连接,消除重复。它是最老牌也最常用的方式,在数据达到几千万条级别时真正显出威力。
但也有相反方向的做法。不把一次销售的信息(客户、商品、数量、日期)拆到三张表里,而是 把整块信息折叠进一个 JSON 块里一起存。这种存储方式叫 文档型(Document) 数据库,MongoDB 最为知名。
把散落在 Excel 三张表里的一次销售折叠进一个 JSON,形状像这样:
{
"sale_date": "2026-04-14",
"customer": { "name": "Alex", "email": "alex@example.com" },
"items": [
{ "name": "Château Margaux 2020", "price": 89000, "quantity": 1 },
{ "name": "Pinot Noir Reserve", "price": 45000, "quantity": 2 }
]
}同样的信息,在关系型里散落在三处,在文档型里则 被打包进同一块。今天学到的关系型的 分离,在文档型里以 嵌套(nesting) 的形式出现。可以这样理解。
整理的仓库与快递箱
把两种做法打个比方:
关系型 就像一个 按种类整理好的大仓库。有客户货架、商品货架、销售记录货架,订单进来时从各个货架取出需要的东西组装起来。即使货物有几万种,仓库依然稳如磐石。
文档型 更像一个 快递箱。把一个订单所需要的所有东西(客户信息、商品清单、数量、日期)装进一个箱子,就这样原样传递出去。收到的一方打开箱子,就能一眼看到这个订单的全部内容。
没有哪种绝对更好,而是 适合不同场景。仓库整理在规模变大时发挥威力,快递箱则启动得快,处理单笔订单更方便。
小规模起步时文档型的优势在哪里
小团队先考虑文档型而不是关系型,原因主要有三点:
- 上手快。不用事先设计好表和关系,发一块 JSON 过去就存好了。对没有开发者的小团队来说,"今天开始今天就能跑"是决定性的。
- 初期业务不需要复杂的关系。关系型的强项要在数据堆到几千万条、多个系统错综交织时才显出来。在"一天几十单、一两家店"的阶段,"把一笔订单所需要的信息打包在一起"反而更简单,也更不容易出错。
- 和事件(event)天然契合。一笔订单本来就是"一位客户 + 若干商品 + 日期"绑在一起的一个事件。把它拆到三张表里再用编号连回去,不如把一个事件打包在一起更贴近人的直觉。
3Min API 之所以默认选择文档型,背景也是这三点。当然,随着时间推移,关系型特有的功能 —— 比如把多张表连起来一次性查询 —— 也会成为刚需。为此,关系型功能也已经在路线图上。但眼下的出发点,是"缩短跑起来之前的时间"。
今天就能上手试的事
读到这里,您其实不用非得了解数据库内部的工作机制,也不用掌握具体的设计方法。这篇文章只有一个目的:让您建立 "把自己业务的数据从脑子里摊到面前的表格中整理" 的感觉。这种感觉仅靠 Excel 就能充分训练。
请依次试下面这三步。全部都可以在 Excel 里完成。
行动 1. 用三张 Excel 工作表画出自己的业务
如果您目前把业务数据一股脑塞在一张 Excel 表里,请打开一个新文件,分成三张工作表。它们分别对应 人、物、交易。不管您的行业是什么,绝大多数业务都能用这三个维度表达。参考上面葡萄酒店的示例表,填 5–10 行真实数据就行。只有一条规则:同一条信息只写在一个地方。人的姓名只写在"人"表里,商品名只写在"物"表里,"交易"表里只写编号。
行动 2. 请 AI 帮您优化 Excel 结构
把填好的文件在 ChatGPT、Claude、Gemini 中任选一个打开并上传,然后这样问:
附件里的电子表格是我 [行业] 业务的数据。为了更好地管理这张 Excel,应该怎么划分工作表和列?请从"避免同一条信息在多处重复"的角度,给我一份非开发者也能落地实施的建议。
这里 AI 返回的应该是"更整洁的 Excel 结构",而不是"数据库设计图"。有这个就够了。走过这个流程一次,您就会亲身感受到"把数据结构化"到底是一种什么样的感觉。
行动 3. 勾勒自动化的方向
Excel 结构整理好以后,最后一步是:"如果将来哪天要把这些数据自动收集起来,应该从哪里开始?"您不需要成为开发者。只要把方向找到就行。
在同一个 AI 对话窗口里,把下面这段提示词整段复制粘贴进去:
请参考下面这份服务文档,告诉我应该按照怎样的顺序开始,才能把我刚才整理好的 Excel 结构以后用这个服务自动收集起来。请用非开发者也能理解的语言,一步一步地说明。
https://3minapi.com/llms-full.txtAI 给您的回答,大致会沿着前面那个快递箱比喻的方向,也就是:"建一个端点,把一笔订单作为一个 JSON 块发过来就好了。" 如果它这么回答,不必惊讶 —— 那正是我们今天学到的关系型的"分离"结构,在文档型里换了个样子变成了"折叠(嵌套)"。
AI 会结合您具体的业务情况引导您的第一步。拿到那份答案,等您准备好以后,可以顺着 如何在没有开发者的情况下创建端点 一步步走下去。
下一期
今天我们看了"装数据的容器"——数据库。光有一个容器好像就够了,但在真实业务里数据会自动堆到容器里,多个系统必须同时看同一个容器。让这件事成真的"窗口"就是下一个话题。
下一期我们要讲的就是这个窗口,也就是 API。请继续跟着葡萄酒店店主,看他的线上商店、POS 和合作餐厅之间是怎么互相交换同一份数据的。
→ 下一期:什么是 API?写给非开发者店主的入门指南
Related Posts
什么是 JSON?写给非开发者店主的入门指南
一份为葡萄酒店店主故事收尾的 JSON 入门指南。从一张 Excel 表出发,沿着键、值、对象、数组的递归结构走一遍,最后还带一个「今天就能动手」的练习:把自己生意里的一桩事写成 JSON。无需任何前置知识。
什么是 API?写给非开发者店主的入门指南
用葡萄酒店店主的故事延续的 API 入门指南。讲清楚 API 为什么是「安全的通道」,为什么自己搭建很不容易,今天又可以动手试点什么,让没有任何基础的读者也能跟得上。
小型企业的AI准备 — 数据、API,以及现在该做的事
AI擅长什么、不擅长什么,以及小型企业必须准备的两件事 — 关于数据和API的实用指南。